原文地址:http://blog.csdn.net/phla_han/article/details/50476406
概念定义
- 机器学习:广泛的定义为 “利用经验来改善计算机系统的自身性能。”,事实上,由于“经验”在计算机系统中主要是以数据的形式存在的,因此机器学习需要设法对数据进行分析,这就使得它逐渐成为智能数据分析技术的创新源之一,并且为此而受到越来越多的关注。
- 数据挖掘:一种解释是“识别出巨量数据中有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程”,顾名思义,数据挖掘就是试图从海量数据中找出有用的知识。
关系
关系:数据挖掘可以认为是数据库技术与机器学习的交叉,它利用数据库技术来管理海量的数据,并利用机器学习和统计分析来进行数据分析。其关系如下图1:
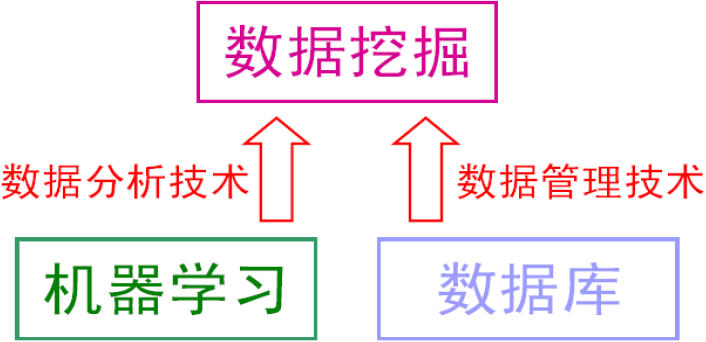
数据挖掘受到了很多学科领域的影响,其中数据库、机器学习、统计学无疑影响最大。粗糙地说,数据库提供数据管理技术,机器学习和统计学提供数据分析技术。由于统计学界往往醉心于理论的优美而忽视实际的效用,因此,统计学界提供的很多技术通常都要在机器学习界进一步研究,变成有效的机器学习算法之后才能再进入数据挖掘领域。从这个意义上说,统计学主要是通过机器学习来对数据挖掘发挥影响,而机器学习和数据库则是数据挖掘的两大支撑技术。
区别
数据挖掘并非只是机器学习在工业上的简单应用,他们之间至少包含如下两点重要区别:
- 传统的机器学习研究并不把海量数据作为处理对象,因此,数据挖掘必须对这些技术和算法进行专门的、不简单的改造。
- 作为一个独立的学科,数据挖掘也有其独特的东西,即:关联分析。简单地说,关联分析就是希望从数据中找出“买尿布的人很可能会买啤酒”这样看起来匪夷所思但可能很有意义的模式。
- 参考:《数据挖掘与机器学习》, by 周志华 ↩