原文地址:https://cosx.org/2016/06/machine-learning-statistics-and-computation/
编辑部按:本文是从张志华老师在第九届中国R语言会议和上海交通大学的两次讲座中整理出来的,点击此处观看幻灯片。张志华老师是上海交通大学计算机科学与工程系教授,上海交通大学数据科学研究中心兼职教授,计算机科学与技术和统计学双学科的博士生指导导师。在加入上海交通大学之前,是浙江大学计算机学院教授和浙江大学统计科学中心兼职教授。张老师主要从事人工智能、机器学习与应用统计学领域的教学与研究,迄今在国际重要学术期刊和重要的计算机学科会议上发表70余篇论文,是美国“数学评论”的特邀评论员,国际机器学习旗舰刊物Journal of Machine Learning Research 的执行编委,其公开课《机器学习导论》和《统计机器学习》受到广泛关注。

大家好,今天我演讲的主题是 “机器学习:统计与计算之恋”。我用了一个很浪漫的名字,但是我的心情是诚惶诚恐的。一则我担心自己没有能力驾驭这么大的主题,二则我其实是一个不解风情之人,我的观点有些可能不符合国内学术界的主流声音。
最近人工智能或者机器学习的强势崛起,特别是刚刚过去的AlphaGo和韩国棋手李世石九段的人机大战,再次让我们领略到了人工智能或机器学习技术的巨大潜力,同时也深深地触动了我。面对这一前所未有的技术大变革,作为10多年以来一直从事统计机器学习一线教学与研究的学者,希望借此机会和大家分享我个人的一些思考和反思。

在这场人工智能发展的盛事里,我突然发现,对我们中国的学者来说,好像是一群看热闹的旁观者。不管你承认还是不承认,事实就是和我一代的或者更早的学者也只能作为旁观者了。我们能做的事情是帮助你们—中国年轻的一代,让你们在人工智能发展的大潮中有竞争力,做出标杆性的成就,创造人类文明价值,也让我有个加油欢呼的主队。
我的演讲主要包含两部分,在第一部分,首先对机器学习发展做一个简要的回顾,由此探讨机器学习现象所蕴含的内在本质,特别是讨论它和统计学、计算机科学、运筹优化等学科的联系,以及它和工业界、创业界相辅相成的关系。在第二部分,试图用“多级”、“自适应”以及 “平均”等概念来简约纷繁多彩的机器学习模型和计算方法背后的一些研究思路或思想。
第一部分:回顾和反思
一、 什么是机器学习
毋庸置疑,大数据和人工智能是当今是最为时髦的名词,它们将为我们未来生活带来深刻的变革。数据是燃料,智能是目标,而机器学习是火箭,即通往智能的技术途径。机器学习大师Mike Jordan和Tom Mitchell 认为机器学习是计算机科学和统计学的交叉,同时是人工智能和数据科学的核心。
It is one of today’s rapidly growing technical fields, lying at the intersection of computer science and statistics, and at the core of artificial intelligence and data science.
— M. I. Jordan
通俗地说,机器学习就是从数据里面挖掘出有用的价值。数据本身是死的,它不能自动呈现出有用的信息。怎么样才能找出有价值的东西呢?第一步要给数据一个抽象的表示,接着基于表示进行建模,然后估计模型的参数,也就是计算,为了应对大规模的数据所带来的问题,我们还需要设计一些高效的实现手段。
我把这个过程解释为机器学习等于矩阵+统计+优化+算法。首先,当数据被定义为一个抽象的表示时,往往形成一个矩阵或者一个图,而图其实也是可以理解为矩阵。统计是建模的主要工具和途径,而模型求解大多被定义为一个优化问题,特别是,频率统计方法其实就是一个优化问题。当然,贝叶斯模型的计算牵涉随机抽样方法。而之前说到面对大数据问题的具体实现时,需要一些高效的方法,计算机科学中的算法和数据结构里有不少好的技巧可以帮助我们解决这个问题。
借鉴Marr的关于计算机视觉的三级论定义,我把机器学习也分为三个层次:初级、中级和高级。初级阶段是数据获取以及特征的提取。中级阶段是数据处理与分析,它又包含三个方面,首先是应用问题导向,简单地说,它主要应用已有的模型和方法解决一些实际问题,我们可以理解为数据挖掘;第二,根据应用问题的需要,提出和发展模型、方法和算法以及研究支撑它们的数学原理或理论基础等,我理解这是机器学习学科的核心内容。第三,通过推理达到某种智能。最后,高级阶段是智能与认知,即实现智能的目标。从这里,我们看到,数据挖掘和机器学习本质上是一样的,其区别是数据挖掘更接地于数据库端,而机器学习则更接近于智能端。
二、 机器学习的发展历程
我们来梳理一下机器学习的发展历程。上个世纪90年代以前,我对此认识不够,了解不深,但我觉得当时机器学习处于发展的平淡期。而1996-2006年是其黄金时期,主要标志是学术界涌现出一批重要成果,比如,基于统计学习理论的SVM和boosting等分类方法,基于再生核理论的非线性数据分析与处理方法,以lasso为代表的稀疏学习模型及应用等等。这些成果应该是统计界和计算机科学界共同努力成就的。
然而,机器学习也经历了一个短暂的徘徊期。这个我感同身受,因为那时我在伯克利的博士后工作结束,正面临找工作,因此当时我导师Mike Jordan教授和我进行了多次交流,他一方面认为机器学习正处于困难期,工作职位已趋于饱满,另一方面他向我一再强调,把统计学引入到机器学习的思路是对的,因为以统计学为基础的机器学习作为一个学科其地位已经被奠定。主要问题是机器学习是一门应用学科,它需要在工业界发挥出作用,能为他们解决实际问题。幸运地是,这个时期很快就过去了。可能在座大多数人对这个时期没有印象,因为中国学术发展往往要慢半拍。
现在我们可以理直气壮地说机器学习已经成为计算机科学和人工智能的主流学科。主要体现在下面三个标志性的事件。
首先,2010年2月,伯克利的Mike Jordan教授和CMU的Tom Mitchell教授同时被选为美国工程院院士,同年5月份,Mike Jordan和斯坦福的统计学家Jerome Friedman又被选为美国科学院院士。我们知道许多著名机器学习算法比如CART、MARS 和GBM等是 Friedman教授等提出。

随后几年一批在机器学习做出重要贡献的学者先后被选为美国科学院或工程院院士。比如,人工智能专家的Daphne Koller,Boosting的主要建立者Robert Schapire,Lasso的提出者Robert Tibshirani, 华裔著名统计学习专家郁彬老师,统计机器机器学习专家的Larry Wasserman,著名的优化算法专家 Stephen Boyd等。同时,机器学习专家、深度学习的领袖Toronto大学Geoffrey Hinton 以及该校统计学习专家Nancy Reid 今年分别被选为美国工程院和科学院的外籍院士。

这是当时Mike给我祝贺他当选为院士时的回信:
Thanks for your congratulations on my election to the National Academy. It’s nice to have machine learning recognized in this way.
因此,我理解在美国一个学科能否被接纳为主流学科的一个重要标志是其代表科学家能否被选为院士。我们知道Tom Mitchell 是机器学习早期建立者和守护者,而Mike Jordan是统计机器学习的奠基者和推动者。
这个遴选机制无疑是先进的,它可以促使学科良性发展,适应社会动态发展和需求。相反,如果某某通过某种方式被评选为本国院士,然后他们就掌握了该国学术话语权和资源分配权。这种机制可能会造成一些问题,比如一些过剩学科或者夕阳学科会得到过多的发展资源。而主流学科则被边缘化。

其次,2011年的图灵奖授予了UCLA的Judea Pearl教授,他主要的研究领域是概率图模型和因果推理,这是机器学习的基础问题。我们知道,图灵奖通常颁给做纯理论计算机科学的学者,或者早期建立计算机架构的学者。而把图灵奖授予Judea Pearl教授具有方向标的意义。
第三,是当下的热点,比如说深度学习、AlphaGo、无人驾驶汽车、人工智能助理等等对工业界的巨大影响。机器学习切实能被用来帮助工业界解决问题。工业界对机器学习领域的才人有大量的需求。不仅仅需要代码能力强的工程师,也需要有数学建模和解决问题的科学家。
让我们具体地看看工业界和机器学习的之间关系。我之前在谷歌研究院做过一年的访问科学家,我有不少同事和以前学生在IT界工作,平时实验室也经常接待一些公司的来访和交流,因此了解一些IT界情况。
我理解当今IT的发展已从传统的微软模式转变到谷歌模式。传统的微软模式可以理解为制造业,而谷歌模式则是服务业。谷歌搜索完全是免费的,服务社会,他们的搜索做得越来越极致,同时创造的财富也越来越丰厚。
财富蕴藏在数据中,而挖掘财富的核心技术则是机器学习。深度学习作为当今最有活力一个机器学习方向,在计算机视觉、自然语言理解、语音识别、智力游戏等领域的颠覆性成就。它造就了一批新兴的创业公司。
三、 统计与计算
我的重点还是要回到学术界。我们来重点讨论统计学和计算机科学的关系。CMU 统计系教授Larry Wasserman最近刚被选为美国科学院院士。他写了一本名字非常霸道的书,《All of Statistics》。在这本书引言部分关于统计学与机器学习有个非常有趣的描述。他认为原来统计是在统计系,计算机是在计算机系,这两个是不相来往的,而且互相都不认同对方的价值。计算机学家认为那些统计理论没有用,不解决问题,而统计学家则认为计算机学家只是在重新建造轮子,没有新意。然而,他认为这个情况现在改变了,统计学家认识到计算机学家正在做出的贡献,而计算机学家也认识到统计的理论和方法论的普遍性意义。所以,Larry写了这本书,可以说这是一本为统计学者写的计算机领域的书,为计算机学者写的统计领域的书。
现在大家达成了一个共识: 如果你在用一个机器学习方法,而不懂其基础原理,这是一件非常可怕的事情。也是由于这个原因,目前学术界对深度学习还是心存疑虑的。深度学习已经展示其强大的实际应用的效果,但其中的原理目前大家还不是太清楚。
让我们进一步地来分析统计与计算机的关系。计算机学家通常具有强的计算能力和解决问题的直觉,而统计学家长于理论分析,具有强的建模能力,因此,两者有很好的互补性。
Boosting,SVM和稀疏学习是机器学习界也是统计界,在近十年或者是近二十年来,最活跃的方向,现在很难说谁比谁在其中做的贡献大。比如,SVM的理论其实很早被Vapnik等提出来了,但计算机界发明了一个有效的求解算法,而且后来又有非常好的实现代码被陆续开源给大家使用,于是SVM就变成分类算法的一个基准模型。再比如,KPCA是由计算机学家提出的一个非线性降维方法,其实它等价于经典MDS。而后者在统计界是很早就存在的,但如果没有计算机界从新发现,有些好的东西可能就被埋没了。
机器学习现在已成为统计学的一个主流方向,许多著名统计系纷纷招聘机器学习领域的博士为教员。计算在统计已经变得越来越重要,传统多元统计分析是以矩阵为计算工具,现代高维统计则是以优化为计算工具。另一方面,计算机学科开设高级统计学课程,比如统计学中的核心课程“经验过程”。
我们来看机器学习在计算机科学占什么样的地位。最近有一本还没有出版的书 “Foundation of Data Science, by Avrim Blum, John Hopcroft, and Ravindran Kannan,”作者之一John Hopcroft是图灵奖得主。在这本书前沿部分,提到了计算机科学的发展可以分为三个阶段:早期、中期和当今。早期就是让计算机可以运行起来,其重点在于开发程序语言、编译原理、操作系统,以及研究支撑它们的数学理论。中期是让计算机变得有用,变得高效。重点在于研究算法和数据结构。第三个阶段是让计算机具有更广泛的应用,发展重点从离散类数学转到概率和统计。那我们看到,第三阶段实际上就是机器学习所关心的。
现在计算机界戏称机器学习“全能学科”,它无所不在。一方面,机器学习有其自身的学科体系;另一方面它还有两个重要的辐射功能。一是为应用学科提供解决问题的方法与途径。说的通俗一点,对于一个应用学科来说,机器学习的目的就是把一些难懂的数学翻译成让工程师能够写出程序的伪代码。二是为一些传统学科,比如统计、理论计算机科学、运筹优化等找到新的研究问题。
四、 机器学习发展的启示
机器学习的发展历程告诉我们:发展一个学科需要一个务实的态度。时髦的概念和名字无疑对学科的普及有一定的推动作用,但学科的根本还是所研究的问题、方法、技术和支撑的基础等,以及为社会产生的价值。
机器学习是个很酷的名字,简单地按照字面理解,它的目的是让机器能象人一样具有学习能力。但在前面我们所看到的,在其10年的黄金发展期,机器学习界并没有过多地炒作“智能”,而是更多地关注于引入统计学等来建立学科的理论基础,面向数据分析与处理,以无监督学习和有监督学习为两大主要的研究问题,提出和开发了一系列模型、方法和计算算法等,切实地解决工业界所面临的一些实际问题。近几年,因应大数据的驱动和计算能力的极大提升,一批面向机器学习的底层架构又先后被开发出来,深度神经网络的强势崛起给工业界带来了深刻的变革和机遇。
机器学习的发展同样诠释了多学科交叉的重要性和必要性。然而这种交叉不是简单地彼此知道几个名词或概念就可以的,是需要真正的融化贯通。Mike Jordan教授既是一流的计算机学家,又是一流的统计学家,所以他能够承担起建立统计机器学习的重任。而且他非常务实,从不提那些空洞无物的概念和框架。他遵循自下而上的方式,即先从具体问题、模型、方法、算法等着手,然后一步一步系统化。Geoffrey Hinton教授是世界最著名的认知心理学家和计算机科学学家。虽然他很早就成就斐然,在学术界名声卓越,但他一直活跃在一线,自己写代码。他提出的许多想法简单、可行又非常有效,因此被称为伟大的思想家。正是由于他的睿智和力行,深度学习技术迎来了革命性的突破。
机器学习这个学科同时是兼容并收。我们可以说机器学习是由学术界、工业界、创业界(或竞赛界)等合力而造就的。学术界是引擎,工业界是驱动,创业界是活力和未来。学术界和工业界应该有各自的职责和分工。学术界职责在于建立和发展机器学习学科,培养机器学习领域的专门人才;而大项目、大工程更应该由市场来驱动,由工业界来实施和完成。
五、 国内外发展现状
我们来看看机器学习在国际的发展现状。我主要看几所著名大学的情况。在伯克利,一个值得深思的举措是机器学习的教授同时在计算机系和统计学都有正式职位,而且据我所知,他们不是兼职,在两个系都有教授课程和研究的任务的。伯克利是美国统计学的发源地,可以说是当今统计学的圣地,然而她兼容并蓄、不固步自封。Mike Jordan教授是统计机器学习的主要建立者和推动者,他为机器学习领域培养了一大批优秀的学生。统计系的主任现在是Mike,然而他早年的教育并没有统计或数学背景。可以说,Berkeley的统计系成就了Mike,反过来他也为Berkeley的统计学发展创造了新的活力,建立了无可代替的功勋。
斯坦福和伯克利的统计是公认世界最好的两个。我们看到,斯坦福统计系的主流方向就是统计学习,比如我们熟知的《Elements of statistical learning》一书就是统计系几位著名教授撰写的。Stanford计算机科学的人工智能方向一直在世界占主导地位,特别在不确定推理、概率图模型、概率机器人等领域成就斐然,他们的网络公开课 《机器学习》、《概率图模型》以及《人工智能》等让世界受益。


CMU是一个非常独特的学校,她并不是美国传统的常春藤大学。可以说,它是以计算机科学为立校之本,它是世界第一个建立机器学习系的学校。Tom Mitchell 教授是机器学习的早期建立者之一和守护者,他一直为该校本科生教《机器学习》课程。然而,这个学校统计学同样强,尤其,她是贝叶斯统计学的世界研究中心。
在机器学习领域,多伦多大学有着举足轻重的地位,她们机器学习研究组云集了一批世界级的学者,在“Science” 和“Nature”发表多篇论文,实属罕见。Geoffrey Hinton 教授是伟大的思想家,但更是践行者。他是神经网络的建立者之一,是BP算法和深度学习的主要贡献者。正是由于他的不懈努力,神经网络迎来了大爆发。Radford Neal 教授是Hinton学生,他在贝叶斯统计领域,特别是关于MCMC做出了一系列的重要工作。
国际发展现状

那么我们来看看国内的现状。总的来说,统计和计算机科学这两个学科处于Larry所说的初期各自为战的阶段。面向大数据的统计学与计算机科学的交叉研究是机遇也是挑战。
我之前在浙江大学曾经参与其统计交叉学科中心的组建,由此对统计界有所了解。统计学在中国应该还是一个弱势学科,最近才被国家定为一级学科。我国统计学处于两个极端,一是它被当作数学的一个分支,主要研究概率论、随机过程以及数理统计理论等。二是它被划为经济学的分支,主要研究经济分析中的应用。而机器学习在统计学界还没有被深度地关注。因此,面向于数据处理、分析的IT和统计学的深度融合有巨大的潜力。
虽然,我并没有跟国内机器学习或者人工智能学术界有深入的接触,但我在国内计算机系工作近8年时间,一直在一线从事机器学习相关的教学与研究,应该对机器学习的现状有一定的发言权。机器学习的确在中国得到了广泛的关注,也取得了一定的成绩,但我觉得高品质的研究成果稀缺。热衷于对机器学习的高级阶段进行一些概念炒作,它们通常没有多大的可执行性;偏爱大项目、大集成,这些本更应该由工业界来实施;而理论、方法等基础性的研究不被重视,认为理论没有用处的观点还大有市场。
计算机学科的培养体系还基本停留在它的早期发展阶段。大多数学校都开设了人工智能与机器学习的课程,但无论是深度还是前沿性都落后于学科的发展,不能适应时代的需要。人才的培养无论质量和数量都无法满足工业界的需求。这也是国内IT公司与国际同类公司技术上有较大差距的关键原因。
第二部分:几个简单的研究思路
在这部分,我的关注则回到机器学习的研究本身上来。机器学习内容博大精深,而且新方法、新技术正源源不断地被提出、被发现。这里,我试图用“多级”、“自适应”以及 “平均”等概念来简约纷繁多彩的机器学习模型和计算方法背后的一些研究思路和思想。希望这些对大家理解机器学习已有的一些模型、方法以及未来的研究有所启发。
1. 多级 (Hierarchical)
首先,让我们来关注“多级 这个技术思想。我们具体看三个例子。
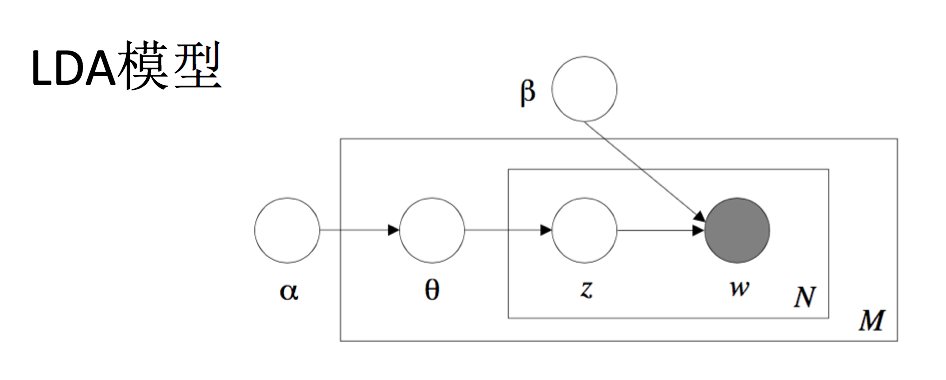
第一个例子是隐含数据模型,它就是一种多级模型。作为概率图模型的一种延伸,隐含数据模型是一类重要的多元数据分析方法。隐含变量有三个重要的性质。第一,可以用比较弱的条件独立相关性代替较强的边界独立相关性。著名的de Finetti 表示定理支持这点。这个定理说,一组可以交换的随机变量当且仅当在某个参数给定条件下,它们可以表示成一组条件随机变量的混合体。这给出了一组可以交换的随机变量的一个多级表示。即先从某个分布抽一个参数,然后基于这个参数,独立地从某个分布抽出这组随机变量。第二,可以通过引入隐含变量的技术来方便计算,比如期望最大算法以及更广义的数据扩充技术就是基于这一思想。具体地,一些复杂分布,比如t-distribution, Laplace distribution 则可以通过表示成高斯尺度混合体来进行简化计算。第三,隐含变量本身可能具有某种有可解释的物理意思,这刚好符合应用的场景。比如,在隐含狄利克雷分配(LDA)模型,其中隐含变量具有某种主题的意思。
Latent Dirichlet Allocation
第二例子,我们来看多级贝叶斯模型。在进行MCMC抽样后验估计时,最上层的超参数总是需要先人为给定的,自然地,MCMC算法收敛性能是依赖这些给定的超参数的,如果我们对这些参数的选取没有好的经验,那么一个可能做法我们再加一层,层数越多对超参数选取的依赖性会减弱。
Hierarchical Bayesian Model
第三例子,深度学习蕴含的也是多级的思想。如果把所有的节点全部的放平,然后全连接,就是一个全连接图。而CNN深度网络则可以看成对全连接图的一个结构正则化。正则化理论是统计学习的一个非常核心的思想。CNN和RNN是两大深度神经网络模型,分别主要用于图像处理和自然语言处理中。研究表明多级结构具有更强的学习能力。
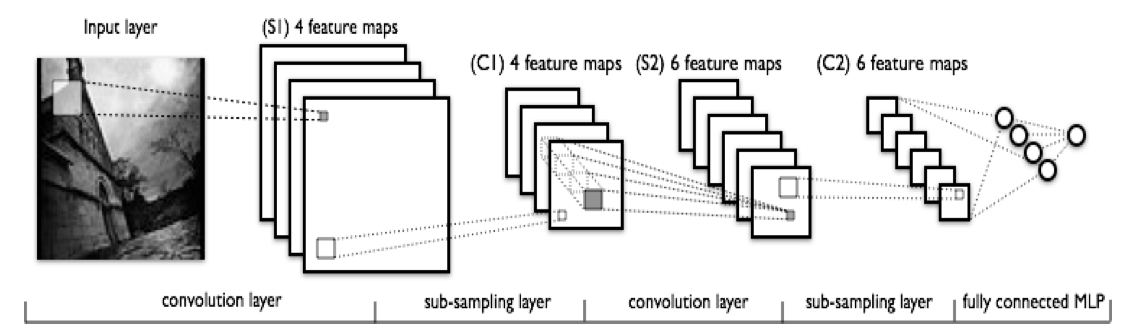
Deep Learning
2. 自适应 (Adaptive)
我们来看自适应这个技术思路,我们通过几个例子来看这个思路的作用。
第一个例子是自适应重要采样技术。重要采样方法通常可以提高均匀采样的性能,而自适应则进一步改善重要采样的性能。
第二个例子,自适应列选择问题。给定一个矩阵A,我们希望从中选取部分列构成一个矩阵C,然后用$CC^+A$去近似原矩阵A,而且希望近似误差尽可能小。这是一个NP难问题。在实际上,可以通过一个自适应的方式,先采出非常小一部分$C_1$,由此构造一个残差,通过这个定义一个概率,然后用概率再去采一部分$C_2$,把$C_1$ 和 $C_2$ 合在一起组成$C$。
第三个例子,是自适应随机迭代算法。考虑一个带正则化的经验风险最小问题,当训练数据非常多时,批处理的计算方式非常耗时,所以通常采用一个随机方式。存在的随机梯度或者随机对偶梯度算法可以得到参数的一个无偏估计。而通过引入自适应的技术,可以减少估计的方差。
第四个例子,是Boosting分类方法。它自适应调整每个样本的权重,具体地,提高分错样本的权重,而降低分对样本的权重。
3. 平均 (Averaging)
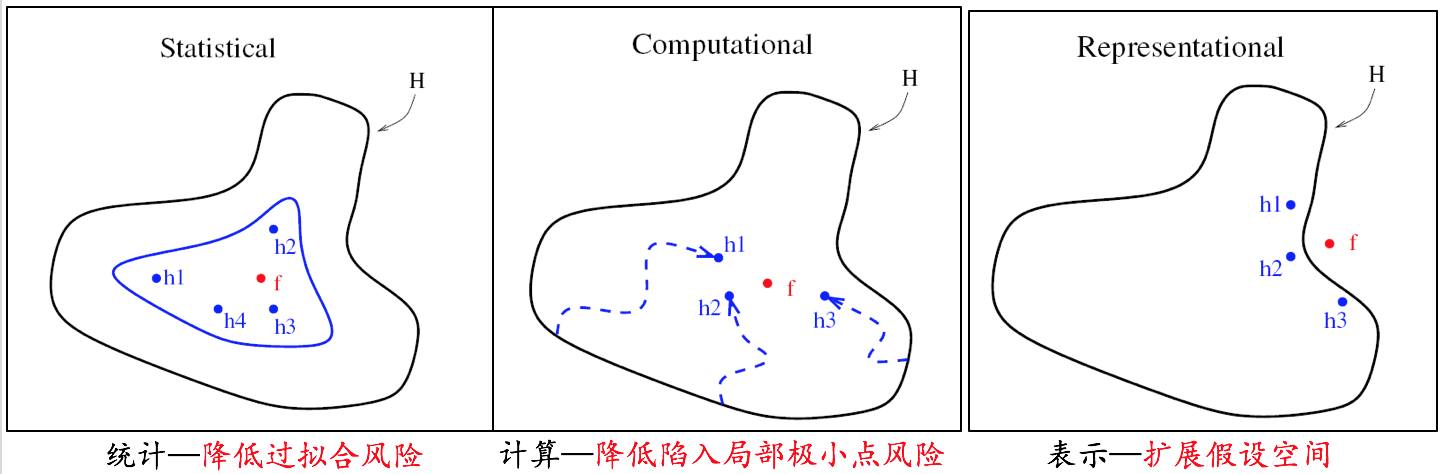
其实,boosting 蕴含着平均思想,即我最后要谈的技术思路。简单地说,boosting是把一组弱分类器集成在一起,形成一个强的分类器。第一好处是可以降低拟合的风险。第二,可以降低陷入局部的风险。第三,可以扩展假设空间。Bagging同样是经典的集成学习算法,它把训练数据分成几组,然后分别在小数据集上训练模型,通过这些模型来组合强分类器。另外这是一个两层的集成学习方式。
经典的Anderson 加速技术则是通过平均的思想来达到加速收敛过程。具体地,它是一个叠加的过程,这个叠加的过程通过求解一个残差最小得到一个加权组合。这个技术的好处,是没有增加太多的计算,往往还可以使数值迭代变得较为稳定。
另外一个使用平均的例子是分布式计算中。很多情况下分布式计算不是同步的,是异步的,如果异步的时候怎么办?最简单的是各自独立做,到某个时候把所有结果平均,分发给各个worker, 然后又各自独立运行,如此下去。这就好像一个热启动的过程。
正如我们已经看到,这些思想通常是组合在一起使用的,比如boosting模型。我们多级、自适应和平均的思想很直接,但的确也很有用。
在AlphaGo和李世石九段对弈中,一个值得关注的细节是,代表Alpha Go方悬挂的是英国国旗。我们知道AlphaGo是由deep mind团队研发的,deep mind是一家英国公司,但后来被google公司收购了。科学成果是世界人民共同拥有和分享的财富,但科学家则是有其国家情怀和归属感。
位低不敢忘春秋大义,我认为我国人工智能发展的根本出路在于教育。先哲说:“磨刀不误砍柴夫”。只有培养出一批又一批的数理基础深厚、计算机动手执行力极强,有真正融合交叉能力和国际视野的人才时,我们才会有大作为。
致谢
上述内容是根据我最近在第九届中国R语言会议和上海交通大学的两次讲座而整理出来的,特别是R会主办方统计之都的同学们帮我做了该次演讲的记录。感谢统计之都的太云、凌秉和象宇的邀请,他们和统计之都的伙伴们正在做一件意义影响深远的学术公益,你们的情怀和奉献给了我信心来公开宣讲自己多年来的真实认识和思考。感谢我的学生们帮助我准备这个讲演报告,从主题的选定,内容的选取,材料的收集以及ppt的制作他们都给了我极大的支持,更重要的是,他们让我在机器学习领域的求索一直不孤独。谢谢大家!
附:演讲幻灯片下载